Denoising Diffusion Null-Space Model
PKU ICLR’23
Backgrounds
考虑不含噪的图像线性逆问题,可以定义为
y=Ax(1)
其中 x∈RN 是原图, A 是线性退化算子,y∈RM 是原图经过退化后得到的图,也称为退化图。对于压缩感知,A 是采样矩阵,y 是测量值。
求解 x^ 的过程需满足以下两个约束
- 数据一致性,即 Ax=y 成立
- 真实性,即 x^∼q(x)
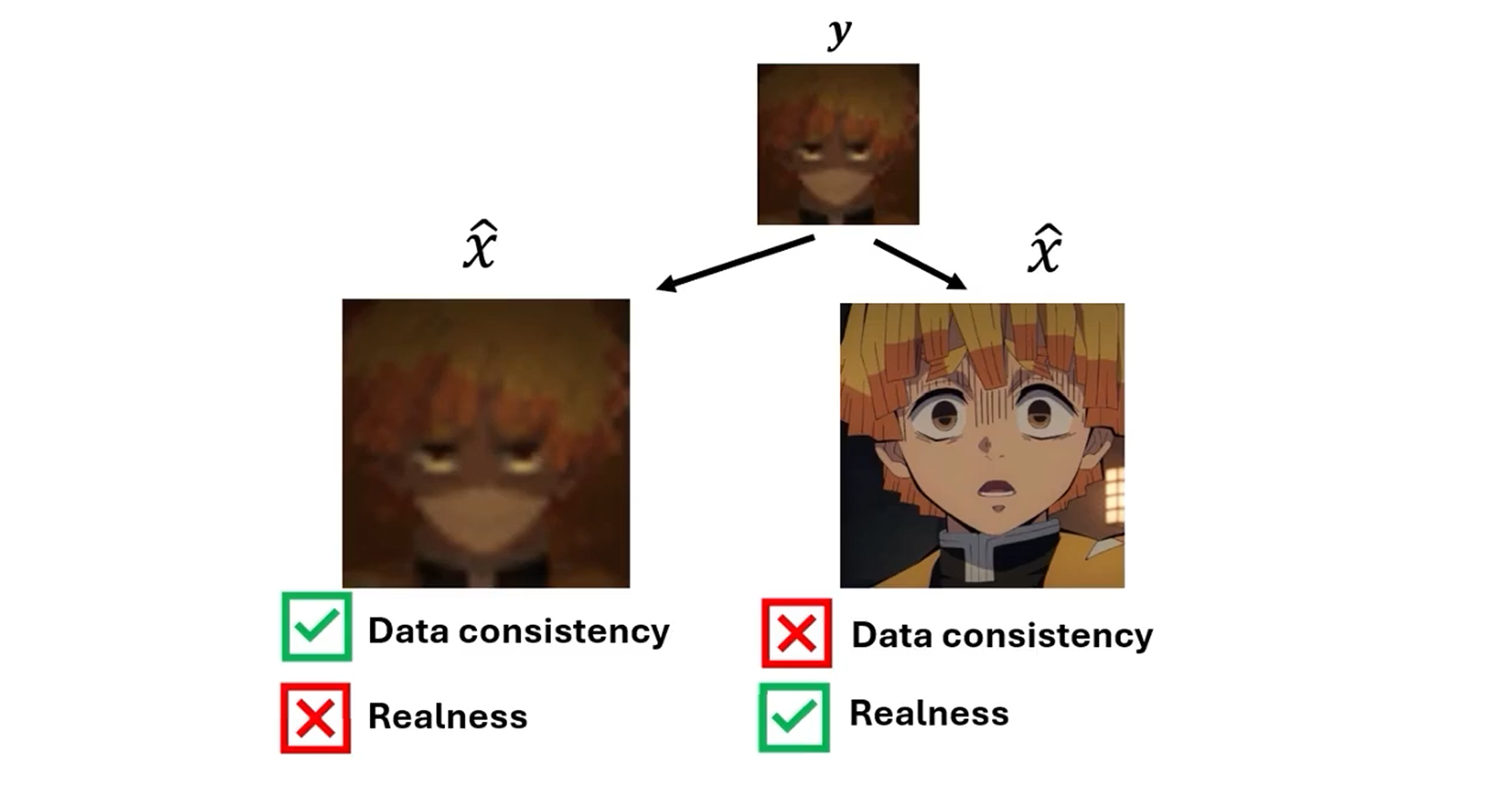
约束 1. 对应保真项,2. 对应正则项如结构先验等,如 CS 中的稀疏性约束。下图分别展示了分别满足约束 1. 2. 的有缺陷的重建,笔者理解的「满足一致性,但不满足真实性」即过于平滑或含噪。

一般而言,容易保证一致性,因为图像逆问题是欠定问题,有 M≪N,从而总是能找出一些 x^ 使得式 (1) 成立。而生成网络从大量自然图片中学习到强大的先验知识,其生成的图片容易保证真实性。那么是否能够从生成模型预测的符合约束 2. 的重建 xr 做进一步变换,得到同时符合约束 1. 的重建呢 ? 这也是本文的关注点,作者提出,可对 xr 进行如下变换
x^=A†y+(I−A†A)xr(2)
式 (2) 应用了 零-值域分解。前项 A†y 为 A 的值域,后项 (I−A†A)xr 为零域。xr 称为零域提取项,使用 xr 构造零域,并补充值域部分,即可得到同时满足约束 1. 2. 的优质重建。验证如下:
Ax^=AA†Ax+A(I−A†A)xr=Ax=y(3)
从而,对任意 xr,经过式 (2) 的构造后都有 y=Ax^,满足一致性约束。下文对其原理进行讲解。
零-值域分解
给定一个矩阵 A∈Rd×D,它的伪逆矩阵 A†∈RD×d 满足 AA†A≡A。当得到 A 和 A† 后,可对任意向量 x∈RD×1 做如下恒等分解
x≡A†Ax+(I−A†A)x(4)
计算 Ax
Ax=AA†Ax+A(I−A†A)x(5)
由伪逆矩阵性质,左侧 AA†Ax=Ax,右侧 A(I−A†A)x=0,将 A†Ax 称为 A 的值域部分,(I−A†A)x 称为零域部分。式 (4) 所示的分解即零-值域分解。
图像逆问题
考虑线性图像变换 y=Ax,我们已知 {x,A,A†},可以求出 y。则式 (4) 可写成
x=A†y+(I−A†A)x(6)
在逆问题中,我们已知 {y,A,A†},从而式 (4) 中的值域 A†y 是可以直接还原的,但零域不行。因此可以把变换过程看成,保留关于退化算子 A 的值域部分,而丢弃零域部分。从而,图像逆问题也可以解释成,通过求解零域部分,并联合已知的值域部分来对原始图像进行预测。这可以写成
x^=A†y+(I−A†A)ϕ(r)(7)
将式 (4) 中 xr 写作 R(x),至此,我们得到了与式 (4) 相同的表达形式,为了保证叙述过程的一致性,下文仍然从式 (7) 出发进行讲解。
梯度下降视角
将式 (7) 变换成
x^=ϕ(r)−A†(y−Aϕ(r))(8)
我们得到了一个熟悉的式子,它是关于一个 ℓ2 损失的梯度下降过程,这个损失即 ϕ(r) 对 y 的 MSE 损失,即
Lϕ=∥Aϕ(r)−y∥22(9)
所以,构造零域并还原原始图像的过程可以看成,用零域提取项 xr 重构一次 y^,然后对由原始图像 x 做线性变换得到的 y 计算 MSE Loss,并进行一次步长为 1 的梯度下降。式 (9) 同时也是传统 DUN 优化目标的一部分,从而,零-值域分解视角与传统的优化算法是殊途同归的。
优化 vs. 零-值域分解
在零-值域分解的视角下,我们要还原零域,如果零域使用一个满足真实性约束的 xr 构造,则补充值域后,即可得到同时满足数据一致性和真实性的高质量重建;在传统优化视角下,我们得到的 x^ 的最终形式与零-值域重建得到的最终形式是一致的,都可以用式 (8) 描述,此时 ϕ(r) 可视为一次含有正则项的优化过程,例如 ISTA-Net 所使用的近端映射优化:
x(k)=r(k−1)−ρΦ†(Φr(k−1)−y)r(k)=proxλ,ϕ(x(k))(10)
为了与式 (7) 保持一致,我们调换了原文公式中的 x 与 r,这两个量本来就是交替迭代的,因此并不会影响最终结果的正确性。这是一个很经典的优化算法求解图像逆问题的迭代过程,即一次针对保真项的线性梯度下降 + 一次针对正则项的非线性优化,根据算法描述不同可解释成滤波、去噪、近端映射等。对于式 (10),(I−ρΦ†Φ)ϕ(r) 等价于零域部分。这也是我们将 xr 写成 ϕ(r) 的原因。
理论上,传统 DUN 进行了端到端的学习,应该可以得到不错的重建效果。但事实上,数据一致性与风格一致性等约束都依靠损失函数来完成,它们只作为优化目标,并不能保证结果与之严格相符。而零-值域分解视角下,使用式 (2) 构造的重建结果严格满足数据一致性要求,并且对 xr 不敏感,这意味着可以专注于零域求解过程,只需要保证生成图片的真实性即可,同时在生成网络 R(⋅) 的选取上提供了较高的自由度。
零域求解
DDNM 及其前作分别使用 Diffusion 和 GAN 作为 R(⋅) 对 xr 进行估计。本文针对 DDNM,其过程如下图所示。
回顾 DDPM 的逆扩散过程,有
pθ(xt−1∣xt)=N(xt−1;μθ(xt,x0),σt2I)(11)
其中
⎩⎪⎪⎪⎨⎪⎪⎪⎧μθ(xt,x0)=1−αˉtαt(1−αˉt−1)xt+1−αˉtαˉt−1(1−αt)x0σt2=βt⋅1−αˉt1−αˉt−1(12)
考虑 x0→xt 的一步加噪过程
xt=αtx0+1−αtεt(13)
这里 εt=εθ(xt,t) 代表噪声估计器所估计的 x0→xt 所加噪声。现在可以反向写出 x0 的表达式 (DDPM 原文 Eq. 9)
x0=αˉt1(xt−1−αˉt⋅εt)(14)
将式 (14) 视为一个重参数化采样,则
q(x0∣xt)=N(x0;αˉt1xt,αˉt1−αˉtI)(15)
从而可将式 (14) 记作 x0∣t,代入式 (11) (12),对 pθ(xt−1∣xt) 重参数化采样,可得
xt−1=1−αˉtαt(1−αˉt−1)xt+1−αˉtαˉt−1(1−αt)x0∣t+σtε(16)
DDNM 在式 (16) 处介入。将 x0∣t 作为零域提取项 xr 代入式 (2) 重建,得到
x^0∣t=A†y+(I−A†A)x0∣t(17)
将式 (17) 修正后的 x^0∣t 代回式 (16) 计算 xt−1,即为 DDNM 逆扩散过程,如上图 (a) 所示。
这里其实有些瑕疵。式 (16) 本身是对式 (11) 所示分布进行重参数化采样得到,而用 x^0∣t 修正 x0∣t 后,其所对应的分布已经变了,实际是一个相对于 pθ 方差不变、均值发生微小偏移的高斯分布。作者也没有给出很好的解释,只能归因于训练域的高斯噪声具有较好的鲁棒性。
笔者认为还有另一种解释。生成模型本身的优化目标也是前文提到的两个约束 (真实性和数据一致性,隐含在 ∥ε−εθ∥22 中),与 x^0∣t←x0∣t 修正目标相同,所以应该可以将修正过程视为添加了动量项,从而加速收敛。
笔者疏忽,式 (11) ~ 式 (17) 按照 DDPM 采样过程对零域重建进行解释。实际上原作是基于 DDIM 采样。
Summary
尚存局限如下。
- 退化算子 A 必须是已知的,且需要通过手动构造等方式获取其伪逆 A†。
- 退化算子 A 必须是线性的。对于非线性算子,不一定存在线性可分的零域和值域。
References
- 探索图像逆问题的本质:零值域分解 - 知乎
- 线性代数 | 伪逆矩阵 - Miya_Official - 博客园
- denoising_diffusion_nullspace_model_ddnm_method_explained_哔哩哔哩_bilibili