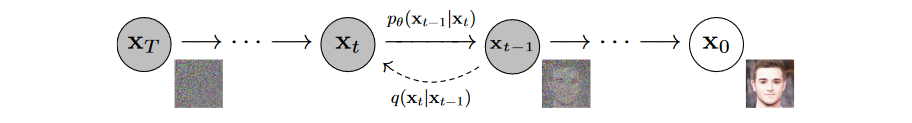DDPM 入门
- 由于渲染器的限制,多行公式只能分配一个标号,以式 (9.8) 代表式 (9) 第 8 行,以此类推。
- 本文的噪声项所使用的符号与原文稍有出入,请读者自行斟酌。
前置
高斯混合模型
一个复杂分布 Pθ 可以用 K 个高斯分布来表示。
Pθ=i=1∑KP(zi)Pθ(x∣zi)(1)
由于 ∫P(z)=1,用一个连续的高斯分布来表示 P(z)∼N(0,1),因此
Pθ=∫P(zi)∗Pθ(x∣zi)(2)
KL 散度
DKL(p∥q)=−x∫p(x)logp(x)q(x)dx(m→∞)(3)
重参数
重参数 (Reparameterization) 是处理期望形式目标函数的一种技巧。
Lθ=Ez∼pθ(z)[f(z)](4)
为使得采样过程能够保留 θ 信息,假设从分布 pθ(z) 中采样可以分解为两个步骤:
- 从无参数分布 q(ϵ) 中采样一个 ϵ;
- 通过变换 z=gθ(ϵ) 生成 z。
那么,式 (4) 就变成了
Lθ=Eε∼q(ε)[f(gθ(ε))](5)
被采样的分布就没有任何参数了,全部被转移到 f 内部。
对高斯分布而言,由于
z∼N(μ,σ2)⇔σz−μ∼N(0,1)(6)
则其重参数化
Ez∼N(z;μθ,σθ2)[f(z)]=Eε∼N(ε;0,1)[f(ε×σθ+μθ)](7)
也就是将「从 N(z;μθ,σθ2) 中采样一个 z」转化为:
- 从 N(ϵ;0,1) 中采样一个 ε
- 计算 z=ε×σθ+μθ
优化目标
初衷是希望生成模型所产生的图片所遵从的概率分布尽可能接近真实世界图片的概率分布。使用 KL 散度描述,得到:
argθminKL(Pdata∥Pθ)(8)
其中 Pθ 是模型所预测的分布,Pdata 为真实分布。对上式做如下变换
argθminKL(Pdata∥Pθ)=argθmin−x∫Pdata(x)logPdata(x)Pθ(x)dx=argθmaxx∫Pdata(x)logPdata(x)Pθ(x)dx=argθmaxx∫Pdata(x)logPθ(x)dx−argθmaxx∫Pdata(x)logPdata(x)dx=argθmaxx∫Pdata(x)logPθ(x)dx=argθmaxEx∼Pdata[logPθ(x)]≈argθmaxi=1∑mlogPθ(xi)=argθmaxlogi=1∏mPθ(xi)=argθmaxi=1∏mPθ(xi)(9)
式 (9.8) 得到新的优化目标 argmaxθi=1∏mPθ(xi)。
Lower Bound
要使式 (9.8) 成立,即极大似然估计 (Maximum Likelihood Estimate)
MLEθ∗=θargmaxPθ(x)(10)
令 q(z∣x) 是某个概率分布 (实际上是加噪过程的分布 qϕ,通常记作 q(x1..T∣x0),ϕ 代表加噪过程的参数),则
log(Pθ(x))=log(Pθ(x))⋅∫q(z∣x)dz=∫log(Pθ(z∣x)Pθ(x,z))q(z∣x)dz=∫log(q(z∣x)Pθ(x,z)⋅Pθ(z∣x)q(z∣x))q(z∣x)dz=∫log(q(z∣x)Pθ(x,z))q(z∣x)dz+KL(q(z∣x)∥Pθ(z∣x))≥∫log(q(z∣x)Pθ(x,z))q(z∣x)dz=Eq(Z∣X)[log(q(z∣x)Pθ(x,z))](11)
式 (11.1) → (11.2),由 Pθ(x,z)=Pθ(x)∗Pθ(z∣x)
式 (11.4),由 KL(p∥q)=∫plogqp≥0
因此,要优化最大对数似然,就是在优化 Evidence Lower Bound (ELBO). 至此,得到初步的优化目标,下面开始讲解 DDPM.
DDPM
Overview

通俗理解 DDPM。允许多步 (T) 生成过程,从而分多次估计噪声 ϵ^t 比一步估计图片 xT→x^0 容易,或者说逐步学习去噪过程的分布 pθ 比直接学习 Pθ 简单。DDPM 的大部分数学框架在更早时候已有之,而该工作的最大贡献其实是用 U-Net 作为噪声估计器调通了这一模型,并得到了不错的效果。
前向扩散过程
给定初始数据分布 x0∼q(x),前向扩散过程向 x0 逐步添加 T 次高斯噪声,得到一系列带噪声图片 x1,...,xT。定义 xt−1→xt 的加噪过程:
q(xt∣xt−1)=N(xt;1−βtxt−1,βtI)(12)
q(x1:T∣x0)=t=1∏Tq(xt∣xt−1)(13)
从而,加噪过程是一个人为定义的马尔可夫链,满足分布 N(xt;1−βtxt−1,βtI),生成 xt−1→xt 的过程只由 {βt,xt−1} 确定。β1,...,βT 是超参数,提前确定 β1,...,βT 后即可得到加噪过程 x1,...,xT 任意一步。
关于 qϕ 的设计。为什么选择 1−βt 和 βt 用于修饰加噪过程的均值和方差,并不知道 DDPM 的前置工作中是否有提及。但在训练过程中,这个设计可以方便地引出 αt 和 αˉt 的定义,从而实现对 x0→xt 的一步加噪。
随着加噪过程的进行, βt 不断 (线性) 增大,即每一步的噪声比例不断升高。注意,此时我们实际上只定义了加噪过程满足的分布 qϕ,尚未定义实际的加噪过程,这部分将在「噪声采样」一节说明。但可以明确的是,当 T→∞,xT 趋近于一个各向独立的高斯分布,视觉上就是一张接近纯粹高斯噪声的「雪花」图。
噪声采样
上一节提到,正向扩散过程向 x0 逐步添加 T 次高斯噪声。这可以写作
xT=x0+η1+η2+...+ηT(14)
反向生成过程则需要通过噪声估计器对噪声进行预测。考虑某一步去噪过程 xt−1←xt,我们希望用 pθ(xt−1∣xt) 去预测 q(xt−1∣xt),由于是期望形式的优化目标,直接采样,梯度信息却无法传递到 θ 上。由式 (7),使用重参数化技巧,每次加噪从 εt∼N(0,I) 采样,令
xt=1−βtxt−1+βtεt−1(15)
此时就实现了将高斯噪声项参数化,得到的 xt 服从式 (12) 分布。
有同学会问,βt 不是超参吗,努力把随机性转移到 εt 做什么,为什么不能直接从式 (12) 采样呢。其实加噪过程是可以这样做的,但重参数化同时也面向去噪过程,下文将说明,后验扩散条件概率 q(xt−1∣xt,x0) 是 Markov 的,q(xt−1∣xt) 则不是,所以才要用 pθ(xt−1∣xt) 预测 q(xt−1∣xt),这个过程就要用神经网络对 θ 优化,从而需要传递梯度。
实际上,先有一个类似式 (14) (15) 的符合 Intuition 的加噪过程,再将其解释为一个分布,这样更加容易理解。
一步加噪
从 x0 和固定序列 {βt∈(0,1)}t=1T 可以直接得到任意一步 xt,从而省去前向迭代。这使得训练过程变得容易,同时方便引出逆扩散过程 q(xt−1∣xt,x0) 的定义。
令 αt=1−βt,αt=∏i=1tαi,有
xt=1−βtxt−1+βtεt−1=1−βt(1−βt−1xt−2+βt−1εt−2)+βtεt−1=αtαt−1xt−2+αt(1−αt−1)εt−2+1−αtεt−1=αtαt−1xt−2+1−αtαt−1ε...=αtx0+1−αtε(16)
式 (16.3) → (16.4),由两个独立高斯分布相加仍为高斯分布,且均值为二者均值和,方差为二者方差和。
后文我们会把式 (16.5) 写成 xt=αtx0+1−αtεt,注意 εt 在这里表示 x0→xt 所加噪声。
由式 (6) (16) 可得
q(xt∣x0)=N(xt;αˉtx0,(1−αˉt)I)(17)
式 (17) 重参数化就是式 (16.5),现在可以实现一步加噪了。
反向生成过程
如果能运行逆扩散过程,即从 q(xt−1∣xt) 中采样,那么就可以从一个随机的高斯分布 N 中重建出一个真实的原始样本。这个过程可以写作一个边缘似然
Pθ(x0)=∫pθ(x0:T)dx1:T(18)
上式中 dx1:T 代表对所有 x1..xT 的可能路径积分。其中
pθ(x0:T)=p(xT)⋅pθ(xT−1∣xT)⋅pθ(xT−2∣xT−1)⋯pθ(x1∣x0)(19)
定义 pθ(xt−1∣xt) 前,首先考虑 q(xt−1∣xt),根据贝叶斯公式,有
q(xt−1∣xt)=q(xt)q(xt∣xt−1)q(xt−1)(20)
研究这个分布有些困难,因为 q(xt),q(xt−1) 未知。但是 q(xt∣x0),q(xt−1∣x0) 已知,可以先由 q(xt−1∣xt,x0) 入手
q(xt−1∣xt,x0)=q(xt∣x0)q(xt∣xt−1,x0)q(xt−1∣x0)(21)
由式 (17)
q(xt−1∣x0)=N(xt−1;αˉt−1x0,(1−αˉt−1)I)(22)
由式 (12) (17) (21) (22)
q(xt∣x0)q(xt∣xt−1,x0)q(xt−1∣x0)∝exp{−21[βt(xt−αtxt−1)2+1−αˉt−1(xt−1−αˉt−1x0)2−1−αˉt(xt−αˉtx0)2]}=exp{−21[(βtαt+1−αˉt−11)xt−12−2(βtαtxt+1−αˉt−1αˉt−1x0)xt−1+C(xt,x0)]}(23)
式 (23.2) 是一个高斯分布。令
⎩⎪⎪⎪⎨⎪⎪⎪⎧μ~(xt,x0)=1−αˉtαt(1−αˉt−1)xt+1−αˉtαˉt−1(1−αt)x0σt~=βt⋅1−αˉt1−αˉt−1(24)
因此
q(xt∣x0)q(xt∣xt−1,x0)q(xt−1∣x0)∼N(xt−1;μ~(xt,x0),σ~tI)(25)
可知,在 x0 已知的前提下,q(xt−1∣xt,x0)=q(xt−1∣xt),反向生成过程也是一个马尔可夫链,满足分布 N(xt−1;μ~(xt,x0),σ~tI).
但实际上,模型在反向过程中并不事先知道 x0,我们最终希望得到的是 q(xt−1∣xt)。考虑 x0=αˉt1(xt−1−αˉt⋅εt),将式 (24) 改写为
⎩⎪⎪⎪⎨⎪⎪⎪⎧μ~(xt,x0)=αt1(xt−1−αˉt1−αtεt)σt~2=(1−αt)⋅1−αˉt1−αˉt−1(26)
εt 在这里表示 x0→xt 所加噪声。这样一来便消去了 x0,并且实际上已经写出了网络要预测的对象 (即 εt),在代码中,我们将用 UNet 作为噪声预测器 εθ 对其分布进行拟合。若写成 εt=εθ(xt,t),则生成 xt−1←xt 的过程只由 {αt,xt} 确定,得到一个近似的遵循高斯分布的马尔可夫链。
根据以上讨论,整理最终表述。前文已经说明,要用 pθ 去拟合真实的 q(xt−1∣xt),因此,pθ(xt−1∣xt) 定义为高斯分布
pθ(xt−1∣xt)=N(xt−1;μθ(xt,t),Σθ(xt,t))(27)
μθ(xt,t) 与 Σθ(xt,t) 在下一节介绍。
整理我们得到的三个分布。前向扩散过程
q(xt∣xt−1)=N(xt;1−βtxt−1,βtI)
x0 已知的逆扩散过程
q(xt−1∣xt,x0)=N(xt;αt1(xt−1−αˉtβtεt),βt⋅1−αˉt1−αˉt−1I)
预测的反向生成过程
pθ(xt−1∣xt)=N(xt−1;μθ(xt,t),Σθ(xt,t))
再谈优化目标
考虑式 (11),对于 DDPM,现在可将其扩展为链式表达的形式,写成
logPθ(x)≥Eqϕ(x1:T∣x0)[logqϕ(x1:T∣x0)Pθ(x0:T)](28)
改写成一个负对数似然,可以使用 Variational Lower Bound 优化,得到的结果是相同的。令
LVLB=Eqϕ(x1:T∣x0)[logpθ(x0:T)qϕ(x1:T∣x0)](29)
可以进一步将式 (29) 展开成几个 KL 散度和熵项的组合 (见附录)
LVLB=Eq[DKL(q(xT∣x0)∥p(xT))+t>1∑DKL(q(xt−1∣xt,x0)∥pθ(xt−1∣xt))−logpθ(x0∣x1)](30)
分别标记 LVLB 中的每个分量,将式 (30) 写成
LVLBwhere LTLtL0=LT+LT−1+⋯+L0=DKL(q(xT∣x0)∥pθ(xT))=DKL(q(xt∣xt+1,x0)∥pθ(xt∣xt+1)),1≤t≤T−1=−logpθ(x0∣x1)(31)
式 (31) 形式的 LVLB 中,LT 为常数项,L0 为重建项,训练过程中通常可忽略。最终优化目标由 Lt 决定,观察 Lt,由 KL 散度含义知,是要让 q 与 pθ 尽量接近。这等价于 μ~(xt,x0)→μθ(xt,t),σ~t→Σθ(xt,t)。注意到 σ~t 只由 α 决定,在 DDPM 中,为了简化过程并保证训练稳定性,直接将 Σθ 固定为 σ~。此时,只需 μ~(xt,x0)→μθ(xt,t),令
μθ(xt,t)=αt1(xt−1−αˉt1−αtεθ(xt,t))(32)
对比式 (26.1) (32),现在优化目标转化为 εθ(xt,t)→εt,使用 MSE 描述
Lsimple(θ):=Et,x0,ε[∥εt−εθ(xt,t)∥2](33)
训练和推理
训练过程的重参数化采样由式 (16.5) 给出。实际训练过程中,为每个训练样本 x0∼q(x0) 选择一个随机时间步 t,一步加噪后使用式 (33) 计算 Loss 并梯度下降。
推理过程。由式 (26) (27) (32),对 pθ(xt−1∣xt) 进行重参数化采样
xt−1=αt1(xt−1−αˉt1−αtεθ(xt,t))+σtε(t>1)(34)
注意 σtε 项,这一项使用 ε∼N(0,I) 对方差进行重参数化,与 εθ 含义不同。在 x1→x0 则直接输出 μθ(x1,1),不添加这一噪声项。
σtε 稍微起到了正则项的作用,可以从结果上近似认为是一种风格损失 Lstyle,也可以认为它补强了高频。去噪过程中不加这一项,则重建出的 x^0 是过于平滑、缺乏纹理的色块。
伪代码
Summary
断断续续数日,终于是整理完了 DDPM 公式,下一步辅以代码强化理解。虽如此,还是有一些基础知识,如流匹配等需要补充。
References
DDPM
- 【较真系列】讲人话-Diffusion Model 全解(原理+代码+公式)_哔哩哔哩_bilibili(讲得很不错,完整看下来基本明白 DDPM 前后向过程都在干什么)
- VictorYuki 视频专辑-VictorYuki 视频合集-哔哩哔哩视频(手写过程,可作为参考)
- 【大白话01】一文理清 Diffusion Model 扩散模型 | 原理图解+公式推导_哔哩哔哩_bilibili(入门 DDPM 看的第一个精讲,还可以)
- 54、Probabilistic Diffusion Model 概率扩散模型理论与完整 PyTorch 代码详细解读_哔哩哔哩_bilibili | 64、扩散模型加速采样算法 DDIM 论文精讲与 PyTorch 源码逐行解读_哔哩哔哩_bilibili(主讲代码)
- 深入浅出扩散模型 (Diffusion Model) 系列:基石 DDPM(人人都能看懂的数学原理篇) - 知乎
- DDPM 解读(一)| 数学基础,扩散与逆扩散过程和训练推理方法 - 知乎
- 漫谈重参数:从正态分布到 Gumbel Softmax - 科学空间 | Scientific Spaces
- Denoising Diffusion Probabilistic Models(DDPM)保姆级解析——附代码实现-CSDN博客
- 此外还看了李宏毅的视频,和之前看老师其他视频的感受一样,需要有些基础再来看,作为巩固增强。否则很多推导都是一语带过,理解起来会有问题。
DDIM
- 【串讲系列】讲人话-Stable Diffusion 全解(原理+代码+公式)之 DDIM + SDXL Turbo_哔哩哔哩_bilibili
DDNM
- denoising_diffusion_nullspace_model_ddnm__method_explained
附录
LVLB 展开